Note
Go to the end to download the full example code.
PDHG and SPDHG for PET reconstruction with a directional TV prior¶
This example demonstrates the primal-dual hybrid gradient (PDHG) algorithm and its stochastic variant (SPDHG) applied to the regularized PET reconstruction problem
where
\(f_\text{data} = \text{NegPoissonLogL}\) – the negative Poisson log-likelihood,
\(f_\text{reg} = \text{MixedL21Norm}\) – the isotropic mixed L2-L1 norm (TV semi-norm),
\(g = \iota_{\geq 0}\) – the indicator function of the non-negative orthant,
\(D = P_{\xi} G\) – the projected finite-difference gradient operator implementing a directional total variation (DTV) structural prior,
\(A\) – the composite PET forward operator (resolution model, TOF projector, attenuation), and
\(s\) – the contamination sinogram.
Both algorithms are implemented through the single spdhg_update() function.
Passing probs=None performs a full PDHG update: all dual blocks are updated
every epoch and the over-relaxed variable is scaled by 1. Passing per-block
selection probabilities activates SPDHG: only one randomly selected block is
updated per mini-iteration and the over-relaxed variable is scaled by
\(1/p_i\), where \(p_i\) is the selection probability of that block.
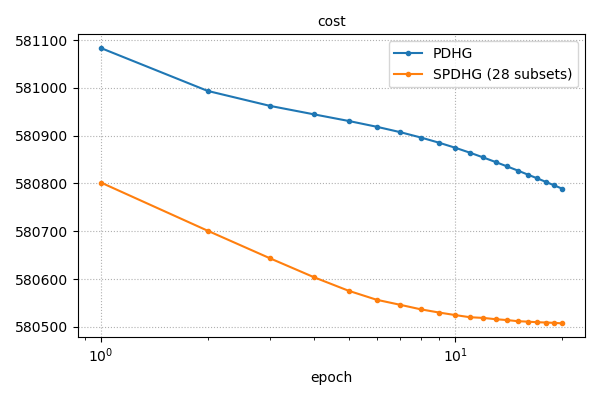
The SPDHG variant is generally cheaper per epoch because it splits the forward operator \(A\) into \(n\) sinogram subsets \(A = A^1 + \ldots + A^n\) and updates one subset at a time.
The example uses simulated TOF sinogram data with a synthetic elliptic-cylinder phantom and a structural prior image derived from the ground-truth activity. MLEM is run for a small number of epochs to provide a warm start for both algorithms.
See [1] and [2] for details on the DTV prior and the SPDHG algorithm (Algorithm 2), and [3] for the step-size rules used here.
from __future__ import annotations
from collections.abc import Sequence
from copy import copy
import matplotlib.pyplot as plt
from parallelproj._examples_utils import show_vol_cuts
from parallelproj._examples_utils import elliptic_cylinder_phantom
import numpy as np
import parallelproj.operators
import parallelproj.functions
import parallelproj.tof
import parallelproj.pet_scanners
import parallelproj.pet_lors
import parallelproj.projectors
from parallelproj import to_numpy_array, Array
from parallelproj._examples_utils import suggest_array_backend_and_device
# To use a specific backend and/or device, replace the None arguments, e.g.:
# xp, dev = suggest_array_backend_and_device(backend="numpy", dev="cpu") or by setting xp and dev manually
xp, dev = suggest_array_backend_and_device(None, None)
Using array API: array_api_compat.torch, device: cpu
Unified PDHG / SPDHG update function¶
Unified PDHG / SPDHG algorithm
Minimize \(\sum_{k=1}^{n+1} f_k(K_k x + c_k) + g(x)\) where the first \(n\) blocks are data subsets and block \(n{+}1\) is the regularizer.
None for full PDHG)probs is None (full PDHG):Passing probs=None performs a full PDHG update (all blocks updated every
call, scale factor 1). Passing per-block probabilities activates SPDHG
(Algorithm 2 from [2]), which touches only one block per
mini-iteration and scales \(\bar{z}\) by \(1/p_i\).
Step sizes
\(S^k = \gamma \, \text{diag}\!\left(\frac{\rho}{A^k \mathbf{1}}\right)\) for data subsets
\(S_D = \gamma \, \frac{\rho}{\|D\|}\) for regularization
\(T^k = \gamma^{-1} \, \frac{\rho \, p_k}{(A^k)^T \mathbf{1}}\) for data subsets
\(T_D = \gamma^{-1} \, \frac{\rho \, p_D}{\|D\|}\) for regularization
\(T = \min(T^1, \ldots, T^n, T_D)\) elementwise
See [2] and [3] for more details.
def spdhg_update(
x: Array,
dual_vars: list[Array], # modified in-place
z_array: Array,
zbar_array: Array,
f_functions: Sequence[parallelproj.functions.FunctionWithConjProx],
ops: Sequence[parallelproj.operators.LinearOperator],
contams: Sequence[Array | None],
g_function: parallelproj.functions.FunctionWithProx,
dual_step_sizes: Sequence[float | Array],
primal_step_size: float | Array,
probs: Sequence[float] | None = None,
) -> tuple[Array, Array, Array]:
"""Unified PDHG / SPDHG update for problems with multiple linear operators.
Minimizes ``sum_i f_i(K_i x + c_i) + g(x)`` where each ``f_i`` has a
known proximal operator of its convex conjugate and ``g`` has a known
proximal operator.
The primal variable is updated first::
x <- prox_{T g}(x - T * zbar)
Then the dual variable(s) are updated depending on the mode:
**Full PDHG mode** (``probs=None``):
All dual variables are updated each call. For every block i::
y_i+ <- prox_{S_i f_i*}(y_i + S_i (K_i x + c_i))
delta_z += K_i^T (y_i+ - y_i)
y_i <- y_i+
The auxiliary variables are then updated as::
z <- z + delta_z
zbar <- z + delta_z (scale factor 1, i.e. p_i = 1)
**SPDHG mode** (``probs`` is a sequence of floats):
One block i_sub is drawn with probabilities ``probs``. Only that
dual variable is updated::
y_i+ <- prox_{S_i f_i*}(y_i + S_i (K_i x + c_i))
delta_z = K_i^T (y_i+ - y_i)
y_i <- y_i+
The auxiliary variables are then updated as::
z <- z + delta_z
zbar <- z + delta_z / p_i (scale factor 1/p_i)
Parameters
----------
x :
Current primal variable. A new array is returned for the updated
primal variable; the original is not mutated.
dual_vars :
List of current dual variables ``y_i``. In PDHG mode all entries are
updated in-place; in SPDHG mode only the selected entry is updated.
z_array :
Auxiliary variable ``z = sum_i K_i^T y_i``.
zbar_array :
Over-relaxed auxiliary variable ``zbar``.
f_functions :
Functions ``f_i``, each exposing a proximal operator of their convex
conjugate via
:meth:`~parallelproj.functions.FunctionWithConjProx.prox_convex_conj`.
ops :
Linear operators ``K_i``, one per function in ``f_functions``.
contams :
Additive offsets ``c_i`` applied after each forward projection
``K_i x``. Pass ``None`` for terms without an offset.
g_function :
Proximal-friendly constraint or regularization function ``g``,
exposing :meth:`~parallelproj.functions.FunctionWithProx.prox`.
dual_step_sizes :
Dual step sizes ``S_i``, one per function/operator pair.
primal_step_size :
Primal step size ``T``.
probs :
Selection probabilities ``p_i`` for each block. When ``None`` (the
default) a full PDHG update is performed (all blocks updated, scale
factor 1). When provided, one block is selected at random and the
over-relaxation is scaled by ``1 / p_i`` (SPDHG mode).
Returns
-------
x :
Updated primal variable.
z_array :
Updated auxiliary variable ``z``.
zbar_array :
Updated over-relaxed auxiliary variable ``zbar``.
"""
# primal update: prox of g (e.g. non-negativity indicator)
x -= primal_step_size * zbar_array
x = g_function.prox(x, primal_step_size)
if probs is None:
# full PDHG: update all dual variables
delta_z = xp.zeros_like(z_array)
for i, (f, op, contam, S) in enumerate(
zip(f_functions, ops, contams, dual_step_sizes)
):
fwd = op(x)
if contam is not None:
fwd += contam
y_plus = f.prox_convex_conj(dual_vars[i] + S * fwd, S)
delta_z += op.adjoint(y_plus - dual_vars[i])
dual_vars[i] = y_plus
z_array += delta_z
zbar_array = z_array + delta_z # scale factor 1
else:
# SPDHG: update one randomly selected block
i_sub = np.random.choice(len(f_functions), p=probs)
fwd = ops[i_sub](x)
if contams[i_sub] is not None:
fwd += contams[i_sub]
y_plus = f_functions[i_sub].prox_convex_conj(
dual_vars[i_sub] + dual_step_sizes[i_sub] * fwd, dual_step_sizes[i_sub]
)
delta_z = ops[i_sub].adjoint(y_plus - dual_vars[i_sub])
dual_vars[i_sub] = y_plus
z_array += delta_z
zbar_array = z_array + delta_z / probs[i_sub] # scale factor 1/p_i
return x, z_array, zbar_array
Input Parameters
# image scale (can be used to simulate more or less counts)
img_scale = 0.1
# number of MLEM epochs used to initialize PDHG and SPDHG
num_epochs_mlem = 10
# number of SPDHG epochs (each = 2 * num_subsets mini-iterations)
num_epochs_spdhg = 20
# number of sinogram subsets for SPDHG
num_subsets = 28
# number of PDHG epochs
num_epochs_pdhg = 20 if dev == "cpu" else num_epochs_spdhg * num_subsets
# regularization weight
beta = 6.0
# step size ratio (used by both PDHG and SPDHG)
gamma = 10.0 / img_scale
# rho parameter controlling the step size margin (used by both PDHG and SPDHG)
rho = 0.9999
# contamination in every sinogram bin relative to mean of trues sinogram
contam = 1.0
# probability of the regularization (gradient) block update per mini-iteration.
# Chosen as 0.5 so that each outer SPDHG epoch (2*num_subsets mini-iterations)
# produces on average num_subsets data-subset updates and num_subsets reg updates:
# E[data subset visits] = p_a * 2 * num_subsets = 2 * (1 - p_g) = 1 per subset
# E[reg visits] = p_g * 2 * num_subsets = num_subsets
p_g = 0.5
# probability of each data subset block update per mini-iteration
p_a = (1 - p_g) / num_subsets
track_cost = True
Simulation of PET data in sinogram space¶
In this example, we use simulated sinogram data for which we first need to setup a sinogram forward model to create a noise-free and noisy emission sinogram.
Setup of the sinogram forward model¶
We setup a linear forward operator \(A\) consisting of an image-based resolution model, a TOF PET projector and an attenuation model.
num_rings = 2
scanner = parallelproj.pet_scanners.RegularPolygonPETScannerGeometry(
xp,
dev,
radius=350.0,
num_sides=28,
num_lor_endpoints_per_side=16,
lor_spacing=4.0,
ring_positions=xp.linspace(-2.5, 2.5, num_rings, device=dev),
symmetry_axis=2,
)
# setup the LOR descriptor that defines the sinogram
img_shape = (40, 40, 4)
voxel_size = (4.0, 4.0, 2.5)
lor_desc = parallelproj.pet_lors.RegularPolygonPETLORDescriptor(
scanner,
radial_trim=170,
sinogram_order=parallelproj.pet_lors.SinogramSpatialAxisOrder.RVP,
)
proj = parallelproj.projectors.RegularPolygonPETProjector(
lor_desc, img_shape=img_shape, voxel_size=voxel_size
)
x_true = elliptic_cylinder_phantom(
xp, dev, image_shape=img_shape, voxel_size=voxel_size
)
# setup a structural prior image
x_struct = -1.0 * xp.sqrt(x_true)
x_struct[x_true == 3] = -1.0
# scale image to get more counts
x_true *= img_scale
Attenuation image and sinogram setup¶
# setup an attenuation image
x_att = 0.01 * xp.astype(x_true > 0, xp.float32)
# calculate the attenuation sinogram
att_sino = xp.exp(-proj(x_att))
Complete sinogram PET forward model setup¶
We combine an image-based resolution model, a non-TOF or TOF PET projector and an attenuation model into a single linear operator.
# enable TOF - uncomment if you want to run TOF recons
proj.tof_parameters = parallelproj.tof.TOFParameters(
num_tofbins=10, tofbin_width=24.0, sigma_tof=24.0
)
# For TOF, att_sino has no TOF-bins dimension while the projector output does.
# broadcast_to adds a trailing singleton via expand_dims and broadcasts it over
# the TOF-bins axis without copying data (zero-stride view).
att_values = (
xp.broadcast_to(xp.expand_dims(att_sino, axis=-1), proj.out_shape)
if proj.tof
else att_sino
)
att_op = parallelproj.operators.ElementwiseMultiplicationOperator(att_values)
res_model = parallelproj.operators.GaussianFilterOperator(
proj.in_shape, sigma=[4.0 / (2.35 * float(vs)) for vs in proj.voxel_size]
)
# compose all 3 operators into a single linear operator
pet_lin_op = parallelproj.operators.CompositeLinearOperator((att_op, proj, res_model))
Simulation of sinogram projection data¶
We setup an arbitrary ground truth \(x_{true}\) and simulate noise-free and noisy data \(d\) by adding Poisson noise.
# simulated noise-free data
noise_free_data = pet_lin_op(x_true)
# generate a constant contamination sinogram
contamination = xp.full(
noise_free_data.shape,
contam * float(xp.mean(noise_free_data)),
device=dev,
dtype=xp.float32,
)
noise_free_data += contamination
# add Poisson noise
np.random.seed(1)
d = xp.asarray(
np.random.poisson(to_numpy_array(noise_free_data)),
device=dev,
dtype=xp.float32,
)
Splitting of the forward model into subsets \(A^k\)¶
Calculate the view numbers and slices for each subset. We use the subset views to setup a sequence of projectors projecting only a subset of views. The slices extract the corresponding subsets from the full data and contamination sinograms.
subset_views, subset_slices = proj.lor_descriptor.get_distributed_views_and_slices(
num_subsets, len(proj.out_shape)
)
_, subset_slices_non_tof = proj.lor_descriptor.get_distributed_views_and_slices(
num_subsets, 3
)
# clear cached LOR endpoints before creating many copies of the projector
proj.clear_cached_lor_endpoints()
# sequence of subset forward operators: resolution model + subset projector + attenuation
pet_subset_linop_seq = []
for i in range(num_subsets):
subset_proj = copy(proj)
subset_proj.views = subset_views[i]
att_values_k = (
xp.broadcast_to(
xp.expand_dims(att_sino[subset_slices_non_tof[i]], axis=-1),
subset_proj.out_shape,
)
if subset_proj.tof
else att_sino[subset_slices_non_tof[i]]
)
subset_att_op = parallelproj.operators.ElementwiseMultiplicationOperator(
att_values_k
)
pet_subset_linop_seq.append(
parallelproj.operators.CompositeLinearOperator(
[subset_att_op, subset_proj, res_model]
)
)
pet_subset_linop_seq = parallelproj.operators.LinearOperatorSequence(
pet_subset_linop_seq
)
Run quick MLEM as initialization¶
x_mlem = xp.ones(pet_lin_op.in_shape, dtype=xp.float32, device=dev)
adjoint_ones = pet_lin_op.adjoint(
xp.ones(pet_lin_op.out_shape, dtype=xp.float32, device=dev)
)
for i in range(num_epochs_mlem):
print(f"MLEM epoch {(i + 1):03} / {num_epochs_mlem:03}", end="\r")
dbar = pet_lin_op(x_mlem) + contamination
x_mlem *= pet_lin_op.adjoint(d / dbar) / adjoint_ones
MLEM epoch 001 / 010
MLEM epoch 002 / 010
MLEM epoch 003 / 010
MLEM epoch 004 / 010
MLEM epoch 005 / 010
MLEM epoch 006 / 010
MLEM epoch 007 / 010
MLEM epoch 008 / 010
MLEM epoch 009 / 010
MLEM epoch 010 / 010
Setup the regularization operator and function objects¶
The finite-difference gradient operator \(G\) is projected by \(P_{\xi}\) to obtain the DTV operator \(D = P_{\xi} G\). Three function objects handle all prox evaluations during PDHG and SPDHG:
data_fid_subsets– list ofNegPoissonLogL, one per subset (used by SPDHG);data_fid_fullis the full-sinogram version used by PDHG and for cost evaluation,nonneg–NonNegativeIndicator, implements \(g = \iota_{\geq 0}\),reg–MixedL21Norm(weighted bybeta), implements \(\beta f_\text{reg}\).
Note
By default NegPoissonLogL evaluates a “safe epsilon”
(shifted Poisson) surrogate: a tiny eps = rel_eps * mean(y) is
added to the measured and the expected data, making all evaluations
finite at the price of a tiny (~``rel_eps``) bias. Prox-driven
algorithms like PDHG / SPDHG never divide by the expected data – the
closed-form dual prox is stable even for zero-count bins – so with
our strictly positive contamination we use exact=True and solve
the exact problem. Keep the default whenever the expected data can
reach zero in bins with counts.
# setup the finite-difference gradient operator
G = parallelproj.operators.FiniteForwardDifference(pet_lin_op.in_shape)
# calculate the joint vector field from the structural prior image
joint_vector_field = G(x_struct)
# setup the projected gradient (DTV) operator
P = parallelproj.operators.GradientFieldProjectionOperator(joint_vector_field, eta=1e-4)
D = parallelproj.operators.CompositeLinearOperator((P, G))
# the strictly positive contamination guarantees positive expected data in
# every bin, so the exact (unmodified) log-likelihood can be used
exact_mode = bool(xp.min(contamination) > 0)
# one data-fidelity function per subset
data_fid_subsets = [
parallelproj.functions.NegPoissonLogL(d[sl], exact=exact_mode)
for sl in subset_slices
]
nonneg = parallelproj.functions.NonNegativeIndicator()
reg = parallelproj.functions.MixedL21Norm(beta=beta)
# full data fidelity for cost evaluation only
data_fid_full = parallelproj.functions.NegPoissonLogL(d, exact=exact_mode)
Setup PDHG – step sizes and primal / dual variables¶
The step sizes follow the rules from [3]. The primal variable is warm-started from the MLEM result; the dual variables are warm-started from the current residuals.
# initialize primal and dual variables
x_pdhg = xp.asarray(x_mlem, copy=True)
y = 1 - d / (pet_lin_op(x_pdhg) + contamination)
w = xp.zeros(D.out_shape, dtype=xp.float32, device=dev)
z = pet_lin_op.adjoint(y) + D.adjoint(w)
zbar = xp.asarray(z, copy=True)
calculate PDHG step sizes
tmp = pet_lin_op(xp.ones(pet_lin_op.in_shape, dtype=xp.float32, device=dev))
tmp = xp.where(tmp == 0, xp.min(tmp[tmp > 0]), tmp)
S_A = gamma * rho / tmp
T_A = (
(1 / gamma)
* rho
/ pet_lin_op.adjoint(xp.ones(pet_lin_op.out_shape, dtype=xp.float32, device=dev))
)
D_norm = D.norm(xp, dev, num_iter=100)
S_D = gamma * rho / D_norm
T_D = (1 / gamma) * rho / D_norm
T = xp.where(
T_A < T_D, T_A, xp.full(pet_lin_op.in_shape, T_D, device=dev, dtype=xp.float32)
)
Run PDHG¶
ys = [y, w]
fs = (data_fid_full, reg)
ops = (pet_lin_op, D)
cons = (contamination, None)
cost_pdhg = np.zeros(num_epochs_pdhg, dtype=np.float32)
for i in range(num_epochs_pdhg):
x_pdhg, z, zbar = spdhg_update(
x_pdhg,
ys,
z,
zbar,
fs,
ops,
cons,
nonneg,
(S_A, S_D),
T,
probs=None, # full PDHG (all blocks updated every epoch)
)
if track_cost:
cost = data_fid_full(pet_lin_op(x_pdhg) + contamination) + reg(D(x_pdhg))
cost_pdhg[i] = cost
print(
f"PDHG epoch {(i+1):04} / {num_epochs_pdhg}, cost {cost_pdhg[i]:.7e}",
end="\r",
)
print("")
PDHG epoch 0001 / 20, cost 5.7692019e+05
PDHG epoch 0002 / 20, cost 5.7682606e+05
PDHG epoch 0003 / 20, cost 5.7679281e+05
PDHG epoch 0004 / 20, cost 5.7677381e+05
PDHG epoch 0005 / 20, cost 5.7675969e+05
PDHG epoch 0006 / 20, cost 5.7674756e+05
PDHG epoch 0007 / 20, cost 5.7673638e+05
PDHG epoch 0008 / 20, cost 5.7672581e+05
PDHG epoch 0009 / 20, cost 5.7671569e+05
PDHG epoch 0010 / 20, cost 5.7670588e+05
PDHG epoch 0011 / 20, cost 5.7669638e+05
PDHG epoch 0012 / 20, cost 5.7668712e+05
PDHG epoch 0013 / 20, cost 5.7667825e+05
PDHG epoch 0014 / 20, cost 5.7666969e+05
PDHG epoch 0015 / 20, cost 5.7666144e+05
PDHG epoch 0016 / 20, cost 5.7665369e+05
PDHG epoch 0017 / 20, cost 5.7664612e+05
PDHG epoch 0018 / 20, cost 5.7663894e+05
PDHG epoch 0019 / 20, cost 5.7663212e+05
PDHG epoch 0020 / 20, cost 5.7662556e+05
Setup SPDHG – block lists, step sizes, and primal / dual variables¶
All blocks (data subsets and regularization) are collected into a single
list. Each mini-iteration, spdhg_update() draws one block at random
according to probs_all and updates only that dual variable.
# blocks: n data subsets + 1 regularization
fs_all = list(data_fid_subsets) + [reg]
ops_all = list(pet_subset_linop_seq) + [D]
contams_all = [contamination[sl] for sl in subset_slices] + [None]
probs_all = [p_a] * num_subsets + [p_g]
Calculate SPDHG step sizes¶
# dual step sizes for data subsets: S^k = gamma * rho / (A^k * 1)
S_A = []
for op in pet_subset_linop_seq:
tmp = op(xp.ones(op.in_shape, dtype=xp.float32, device=dev))
tmp = xp.where(tmp == 0, xp.min(tmp[tmp > 0]), tmp)
S_A.append(gamma * rho / tmp)
# dual step size for regularization (reuse D_norm computed for PDHG above)
S_D = gamma * rho / D_norm
S_all = S_A + [S_D]
# primal step size contributions: T^k = rho * p_k / (gamma * (A^k)^T * 1)
T_candidates = xp.zeros(
(num_subsets + 1,) + tuple(pet_lin_op.in_shape), dtype=xp.float32, device=dev
)
for k, op in enumerate(pet_subset_linop_seq):
adj_ones_k = op.adjoint(xp.ones(op.out_shape, dtype=xp.float32, device=dev))
T_candidates[k] = (rho * p_a / gamma) / adj_ones_k
T_candidates[-1] = xp.full(
pet_lin_op.in_shape,
(rho * p_g / gamma) / D_norm,
device=dev,
dtype=xp.float32,
)
# final primal step size: elementwise minimum over all blocks
T = xp.min(T_candidates, axis=0)
del T_candidates # free memory
Initialize primal and dual variables¶
x_spdhg = xp.asarray(x_mlem, copy=True)
# warm-start dual variables for data subsets
ys = [
1 - d[sl] / (pet_subset_linop_seq[k](x_spdhg) + contamination[sl])
for k, sl in enumerate(subset_slices)
]
# zero-initialize the regularization dual variable (no warm-start for SPDHG)
w = xp.zeros(D.out_shape, dtype=xp.float32, device=dev)
ys_all = ys + [w]
# initialize z = sum_k (A^k)^T y^k + D^T w and zbar = z
z = xp.zeros(pet_lin_op.in_shape, dtype=xp.float32, device=dev)
for k, op in enumerate(pet_subset_linop_seq):
z += op.adjoint(ys[k])
z += D.adjoint(w)
zbar = xp.asarray(z, copy=True)
Run SPDHG¶
Each outer epoch consists of 2 * num_subsets mini-iterations.
In each mini-iteration spdhg_update() randomly draws one block
according to probs_all (probability p_a per data subset,
p_g for the regularization block) and updates only that dual variable.
With p_g = 0.5 and p_a = (1 - p_g) / num_subsets, the expected
number of updates per outer epoch is:
p_a * 2 * num_subsets = 1update per data subset (one full pass)
p_g * 2 * num_subsets = num_subsetsregularization updates
so each outer SPDHG epoch consists of one pass over all data subsets
plus num_subsets regularization gradient steps.
cost_spdhg = np.zeros(num_epochs_spdhg, dtype=np.float32)
for i in range(num_epochs_spdhg):
for _ in range(2 * num_subsets):
x_spdhg, z, zbar = spdhg_update(
x_spdhg,
ys_all,
z,
zbar,
fs_all,
ops_all,
contams_all,
nonneg,
S_all,
T,
probs=probs_all,
)
if track_cost:
cost = data_fid_full(pet_lin_op(x_spdhg) + contamination) + reg(D(x_spdhg))
cost_spdhg[i] = cost
print(
f"SPDHG epoch {(i+1):04} / {num_epochs_spdhg}, cost {cost_spdhg[i]:.7e}",
end="\r",
)
print("")
SPDHG epoch 0001 / 20, cost 5.7662375e+05
SPDHG epoch 0002 / 20, cost 5.7653000e+05
SPDHG epoch 0003 / 20, cost 5.7647538e+05
SPDHG epoch 0004 / 20, cost 5.7644019e+05
SPDHG epoch 0005 / 20, cost 5.7641575e+05
SPDHG epoch 0006 / 20, cost 5.7639938e+05
SPDHG epoch 0007 / 20, cost 5.7638825e+05
SPDHG epoch 0008 / 20, cost 5.7638062e+05
SPDHG epoch 0009 / 20, cost 5.7637494e+05
SPDHG epoch 0010 / 20, cost 5.7637081e+05
SPDHG epoch 0011 / 20, cost 5.7636688e+05
SPDHG epoch 0012 / 20, cost 5.7636425e+05
SPDHG epoch 0013 / 20, cost 5.7636219e+05
SPDHG epoch 0014 / 20, cost 5.7636069e+05
SPDHG epoch 0015 / 20, cost 5.7635906e+05
SPDHG epoch 0016 / 20, cost 5.7635819e+05
SPDHG epoch 0017 / 20, cost 5.7635675e+05
SPDHG epoch 0018 / 20, cost 5.7635594e+05
SPDHG epoch 0019 / 20, cost 5.7635512e+05
SPDHG epoch 0020 / 20, cost 5.7635494e+05
Visualizations¶
vmax = 1.2 * float(xp.max(x_true))
fig_true, _, widgets_true = show_vol_cuts(
x_true,
voxel_size=voxel_size,
vmin=0,
vmax=vmax,
fig_title="true image",
)
fig_true.show()
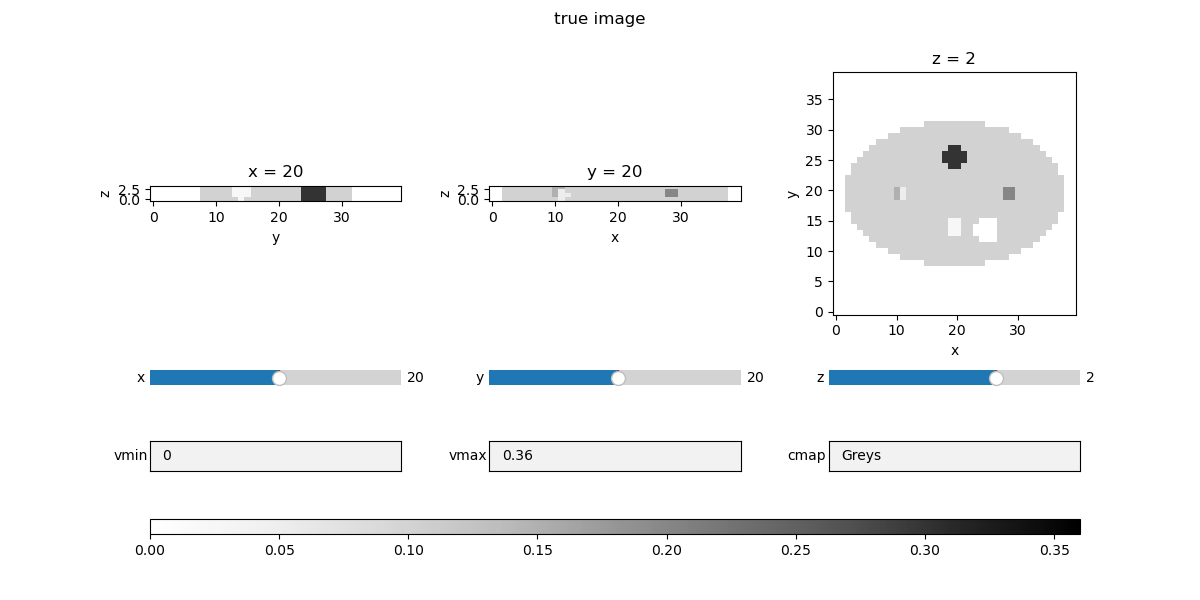
fig_mlem, _, widgets_mlem = show_vol_cuts(
x_mlem,
voxel_size=voxel_size,
vmin=0,
vmax=vmax,
fig_title=f"MLEM {num_epochs_mlem} epochs",
)
fig_mlem.show()
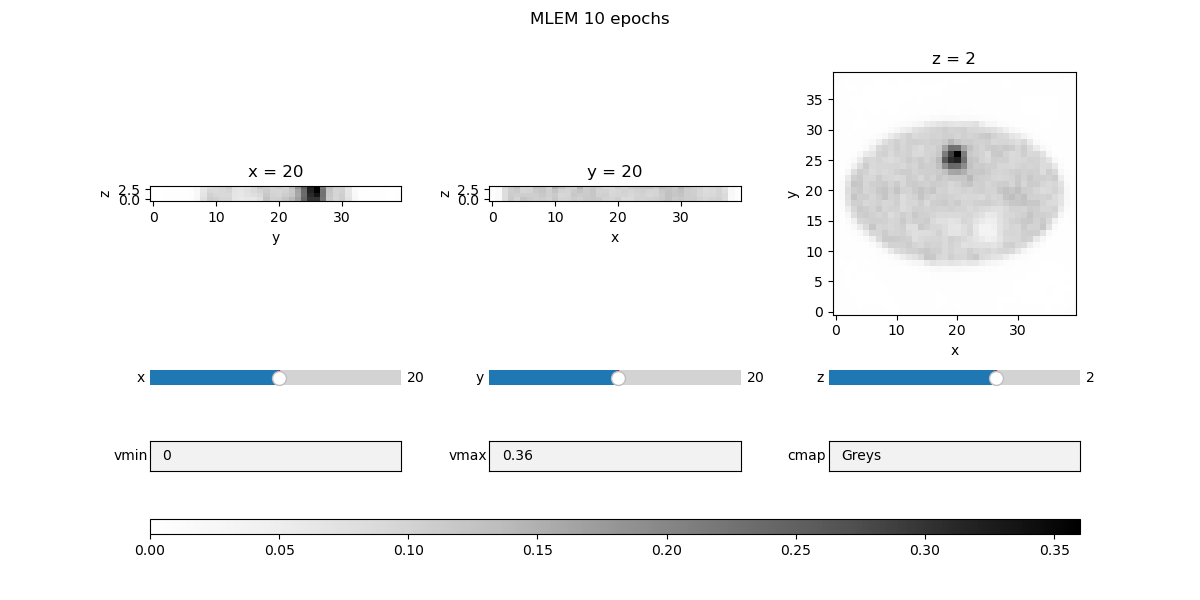
fig_pdhg, _, widgets_pdhg = show_vol_cuts(
x_pdhg,
voxel_size=voxel_size,
vmin=0,
vmax=vmax,
fig_title=f"DTV PDHG {num_epochs_pdhg} epochs",
)
fig_pdhg.show()
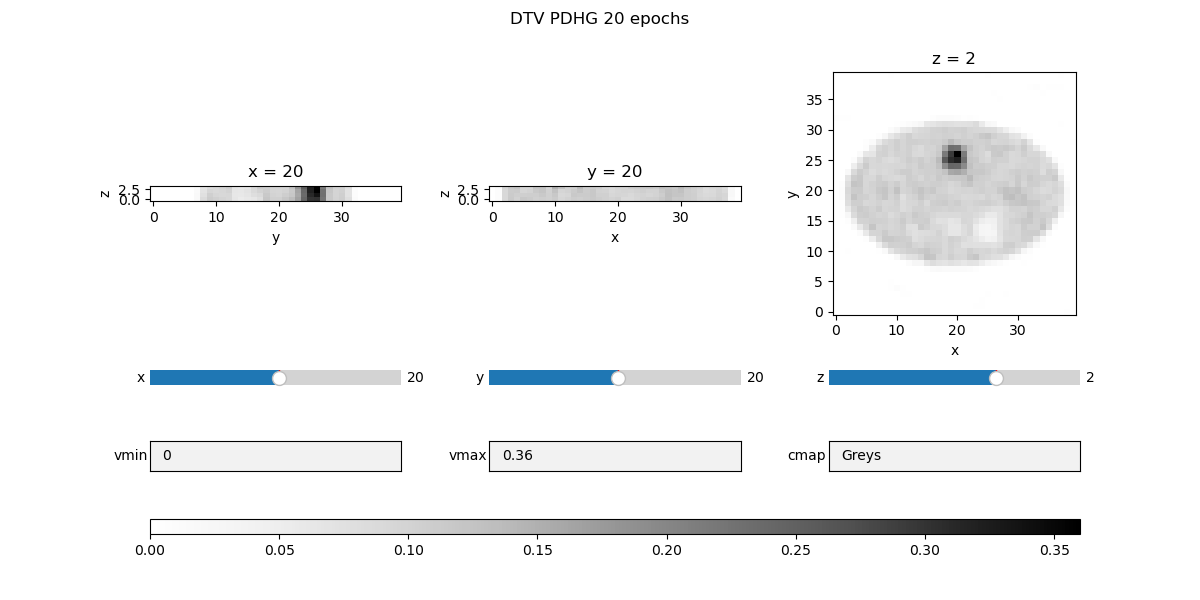
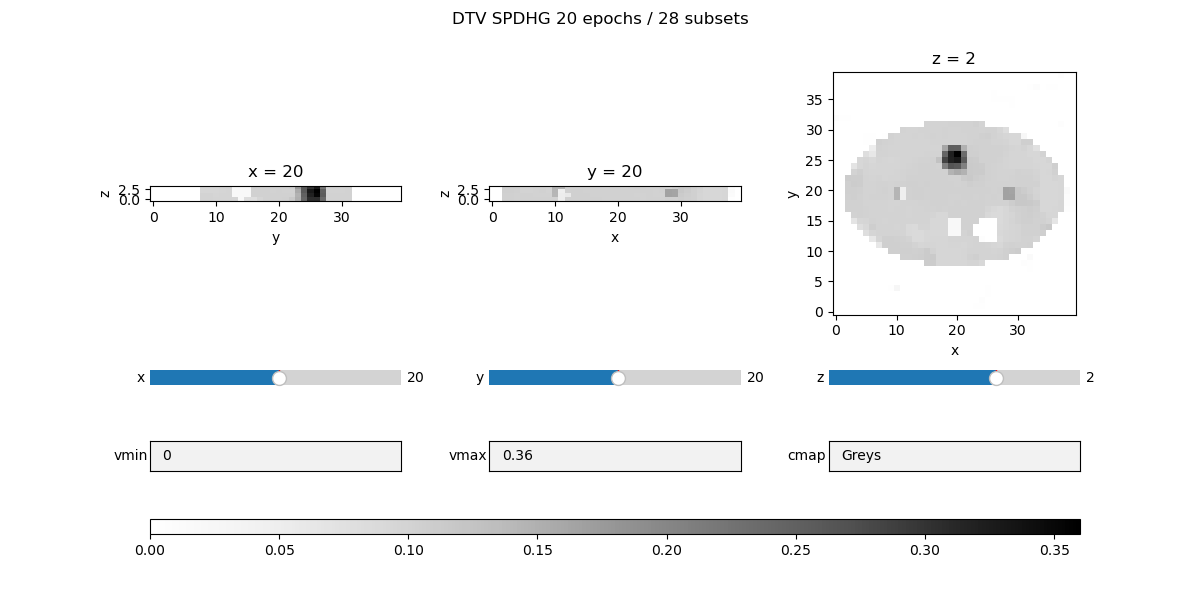
fig_spdhg, _, widgets_spdhg = show_vol_cuts(
x_spdhg,
voxel_size=voxel_size,
vmin=0,
vmax=vmax,
fig_title=f"DTV SPDHG {num_epochs_spdhg} epochs / {num_subsets} subsets",
)
fig_spdhg.show()
fig_struct, _, widgets_struct = show_vol_cuts(
x_struct, voxel_size=voxel_size, fig_title="structural image"
)
fig_struct.show()
if track_cost:
fig2, ax2 = plt.subplots(1, 1, figsize=(6, 4), tight_layout=True)
ax2.semilogx(np.arange(1, num_epochs_pdhg + 1), cost_pdhg, ".-", label=f"PDHG")
ax2.semilogx(
np.arange(1, num_epochs_spdhg + 1),
cost_spdhg,
".-",
label=f"SPDHG ({num_subsets} subsets)",
)
ax2.grid(ls=":")
ax2.legend()
ax2.set_xlabel("epoch")
ax2.set_title("cost", fontsize="medium")
fig2.show()
References
Total running time of the script: (1 minutes 19.148 seconds)